Nodes Browser
ComfyDeploy: How ComfyUI-Open-Sora-I2V works in ComfyUI?
What is ComfyUI-Open-Sora-I2V?
Another comfy implementation for the short video generation project hpcaitech/Open-Sora, supporting latest V2 and V3 models as well as image to video functions, etc.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI-Open-Sora-I2Vand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI-Open-Sora-I2V
Another comfy implementation for the short video generation project hpcaitech/Open-Sora. Supports latest V1.2 and V1.1 models as well as image to video functions, etc.
Installation
pip install packaging ninja
pip install flash-attn --no-build-isolation
git clone https://www.github.com/nvidia/apex
cd apex
sudo python setup.py install --cuda_ext --cpp_ext
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121
cd ComfyUI/custom_nodes
git clone https://github.com/bombax-xiaoice/ComfyUI-Open-Sora-I2V
pip3 install -r ComfyUI-Open-Sora-I2V/requirements.txt
If hpcaitech/Open-Sora standalone mode or chaojie/ComfyUI-Open-Sora has previously runned under the same environment, then opensora may have been installed as a python package, please uninstall it first
pip3 list | grep opensora
pip3 uninstall opensora
Configurations and Models
| Configuration | Model Version | VAE Version | Text Encoder Version | Frames | Image Size | | --------------------------------- | ------------- | ----------- | -------------------- | ------ | ---------- | | opensora-v1-2 | STDiT3 | OpenSoraVAE_V1_2 | T5XXL | 2,4,8,1651 | Many, up to 1280x720 | | opensora-v1-1 | STDiT2 | VideoAutoEncoderKL | T5XXL | 2,4,8,1616 | Many | | opensora | STDiT | VideoAutoEncoderKL | T5XXL | 16,64 | 512x512,256x256 | | pixart | PixArt | VideoAutoEncoderKL | T5XXL | 1 | 512x512,256x256 |
For opensora-v1-2 and opensora-v1-1 as well as VAEs and t5xxl, model files can be automatically downloaded from huggingface. But for older opensora and pixart, please manually download model files to models/checkpoints/ under comfy home directory
Customized Models
-
Older
opensoraandpixartdo not support auto download, download them to models/checkpoints/ under comfy home directory. Then usecustom_checkpointto choose the downloaded folder or file (.json/.safetensors sharing same filename except for their extensions) -
Can assign alternative model other than what the configuration defines. For example, download https://huggingface.co/hpcai-tech/OpenSora-STDiT-v2-stage2 to a folder under models/checkpoints, then use
custom_checkpointto override the default hpcai-tech/OpenSora-STDiT-v2-stage3 model -
If someones had played with comfy for a while, they may already have some useful files in models/vae and models/clip under comfy home directory. Such as vae-ft-ema-560000-ema-pruned, t5xxl_fp8_e4m3fn.safetensors or t5xxl_fp16.safetensors, which can also be used by
custom_vaeandcustom_clipdirectly
Text to Video
-
Use Open Sora Text Encoder or whatever comfy t5xxl nodes as the inputs of
positiveandnegativefor Open Sora Sampler, and skip thereferenceinput -
Use OpenSora's default null embedder if the
negative_promptis left empty -
Camera motion, motion strength and aesthetic score may only apply to
opensora-v1-2(and does not work all the time). One can also put these instructions at the end ofpositive_promptdirectly, in format off'{positive_prompt}. aesthetic score: {aestheic_score:.1f}. motion score: {motion_sthrenth:.1f}. camera motion: {camera_motion}
Image to Video
-
Input one single image (encoded as LATENT) as the starting frame of the output video clip (should align image size). Can skip the inputs
positiveandnegativefor Open Sora Sampler (prompts encoded as CONDITIONGINGs). -
Or, input two images as the starting and ending frames of the output video clip. These two images should be relevant enough to ensure motion quality. (use Latent Batch from WAS-Node-Suite after each image is encoded as LATENT individually)
-
Or, input multiple images of another video to serve as frame interpolation.
-
Can skip
positiveandnegative. Or, if verbal descriptions are still necessary, make sure to make them as consistent to the reference image(s) as possible. Otherwise, video frames may abruptly jump between reference image(s) to verbal generations. May consider applying microsoft/Florence-2-large's more detailed caption task to generate a base prompt.
Text To Video Example
Drag the following image into comfyui, or open workflow custom_nodes/ComfyUI-OpenSora-I2V/t2v-opensora-v1-2-comfy-example.json
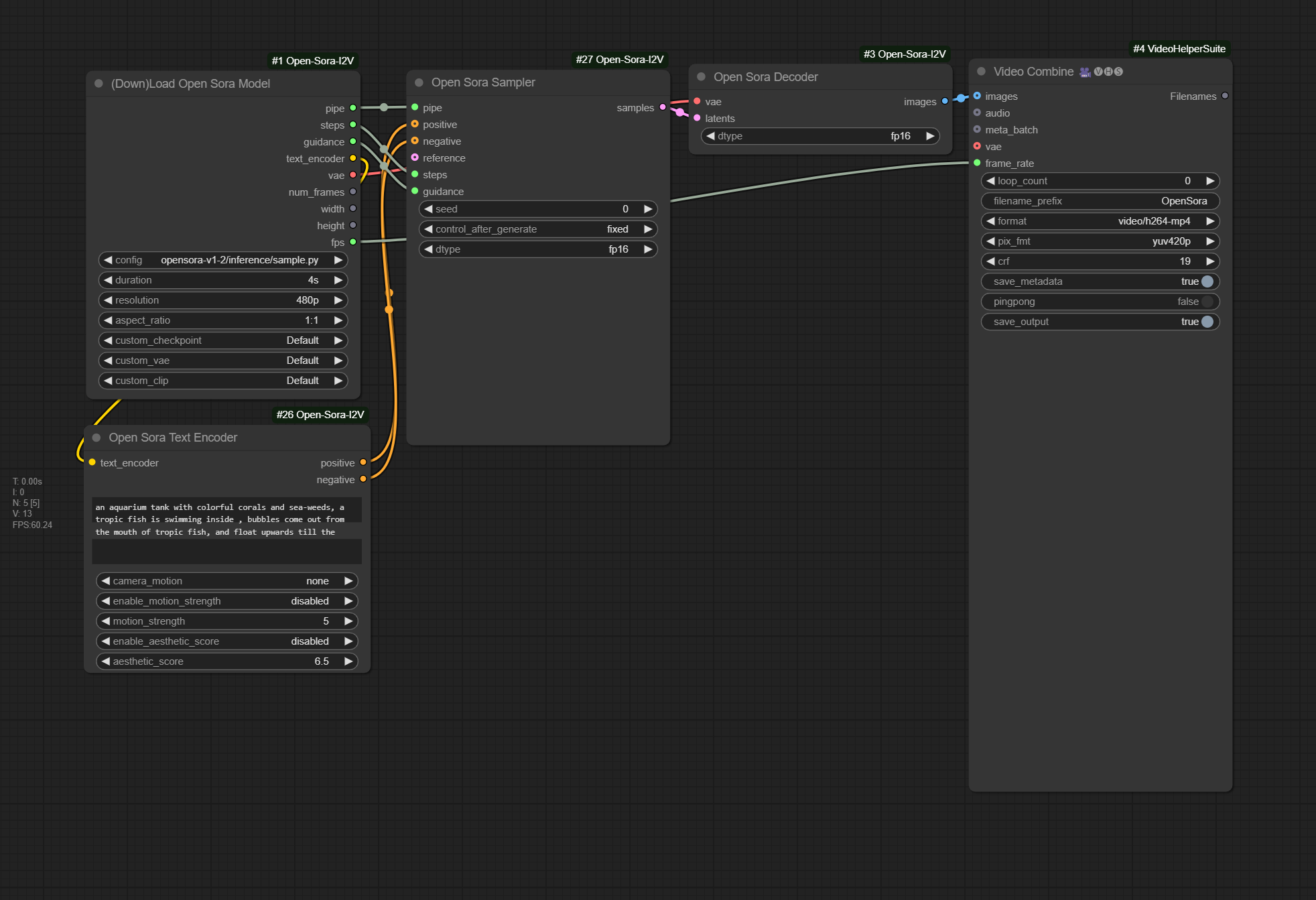
Results run under comfy
https://github.com/user-attachments/assets/350cd72b-e7e0-43dd-be97-a978d9d1b500
Image To Video Example
Drag the following image into comfyui, or open workflow custom_nodes/ComfyUI-OpenSora-I2V/i2v-opensora-v1-2-comfy-example.json
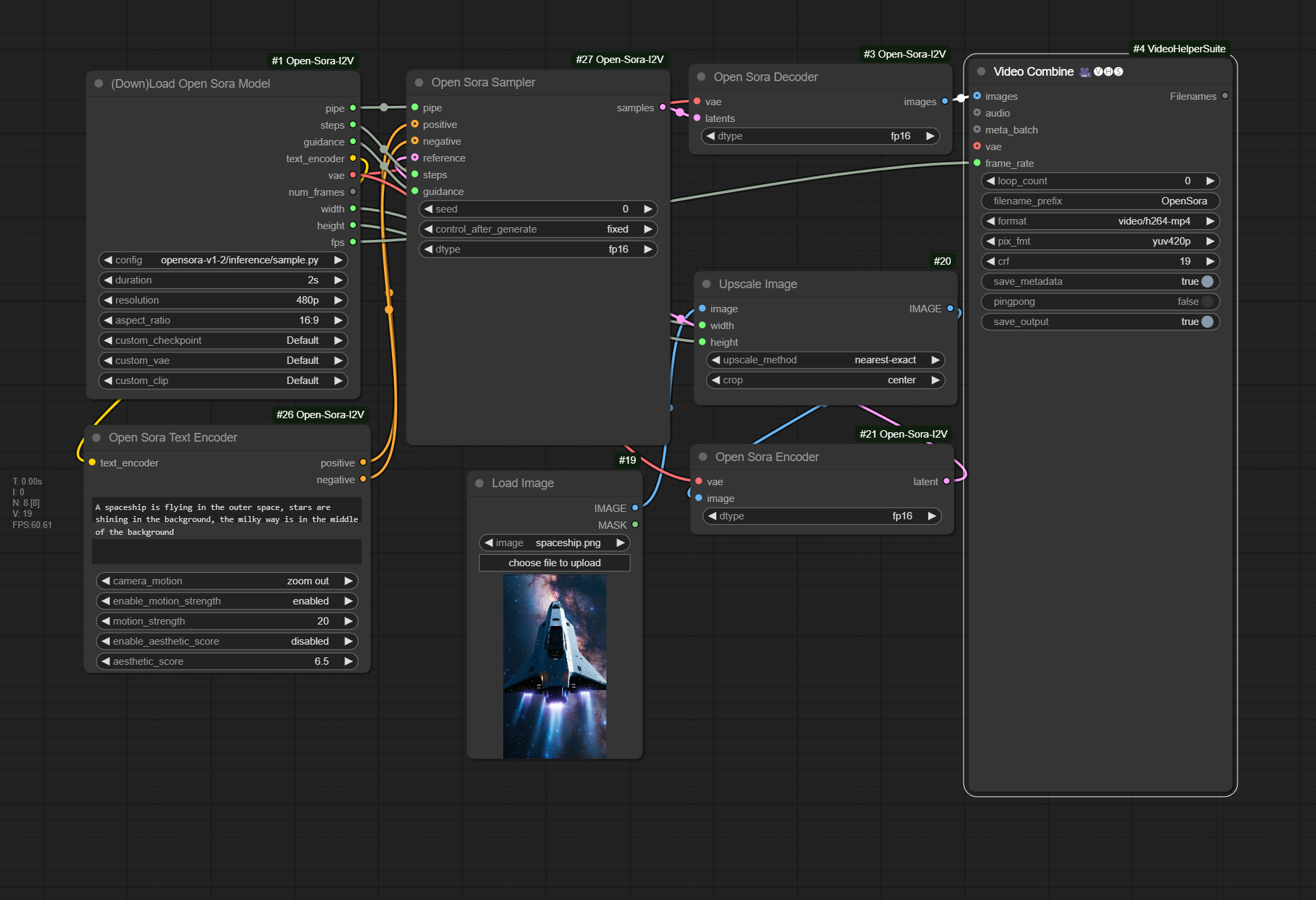
Results run under comfy
https://github.com/user-attachments/assets/0d2ee49c-4d95-4e45-bc7b-a05141ca038e
Tips
-
fp16 is the recommended dtype for Open Sora Sampler, Encoder and Decoer. One can play around other dtypes. But not all combinations work. For instance, Sampler won't work with fp32 under the default flash-attention mode. Also, Video Combine node won't accept bf16 images.
-
Make sure that the input of
referenceto Open Sora Sampler shares the same width and height as the loaded model is configured. Use Upscale Image or similar node to resize reference image(s) before running Open Sora Encoder. -
One can play with alternative text encoder as the input of
positiveandnegativeto Open Sora Sampler. In such case, one can setcustom_clipasSkipin Loader to spare unnecessary loading time of text encoder. -
One can also play with alternative VAEs as the input of Open Sora Encoder and Decoder, but VAE can't be skipped in
custom_vaeas the initializing of checkpoint model has dependencies on VAE. -
The resolution is the size of the shorter edge under 16:9 or 9:16 aspect ratios. For example, if you choose 720p, outputs can be 720x1280 or 1280x720. Surprisingly, if you set aspect ratio to 1:1, the output size of 720p is actually 960x960. This is how Open-Sora's original gradio demo works, so I choose to keep it as it is.
-
Setting a lower
motion_strength(such as 5) can make messy moves and abrupt changes between consecutive frames less likely. -
Had tried my best to minimize code changes under the
opensoracode directory derived from the original hpcaitech/Open-Sora project. But utils/inference_utils.py, utils/ckpt_utils.py and a few files under scheduler/ are still modified in order to support comfy features such as seperate text-encoder node, progress bar, preview, etc.